Intro
Este post es un reciclado del primer post medio serio de R & flowers 4, que es un blog que aún existe pero en breve lo borraré. Resulta que me dio por aprender (un poquito) de web scrapping, así que se ocurrió “scrapear” una tabla de la Wikipedia, concretamente esta tabla. Es una tabla con información sobre los municipios de Teruel; entre otras cosas, se puede ver sus altitudes.
Con ello podré ver que pueblo de Teruel está más alto. Con lo fácil que sería hacerlo desde la propia wiki: como la tabla es un <table class="sortable wikitable" border="1"> solo hay que pinchar en la columna apropiada de la tabla para verlo; pero para aprender, obviously, hay que hacerlo con R!!!
Durante el proceso me lié un poco y acabé usando dos paquetes de R, webshot y magick. El primero es para hacer webshoots y el segundo para manipular imágenes. Seguramente hablaré de ellos en un post porque quiero modificar el logo y el avatar del blog.
Scrapeando una tabla de la Wiki
Volvemos al objetivo inicial: aprender sobre web scrapping. El impulso para hacer scrapping me lo dio este post, pero no lo entiendo bien del todo, así que ya veremos cuando lo aprendo bien; de momento a capón y espero aprender durante el proceso.
La tabla de la que quiero obtener la información está aquí y en el momento de escribir el blog tenía esta pinta:
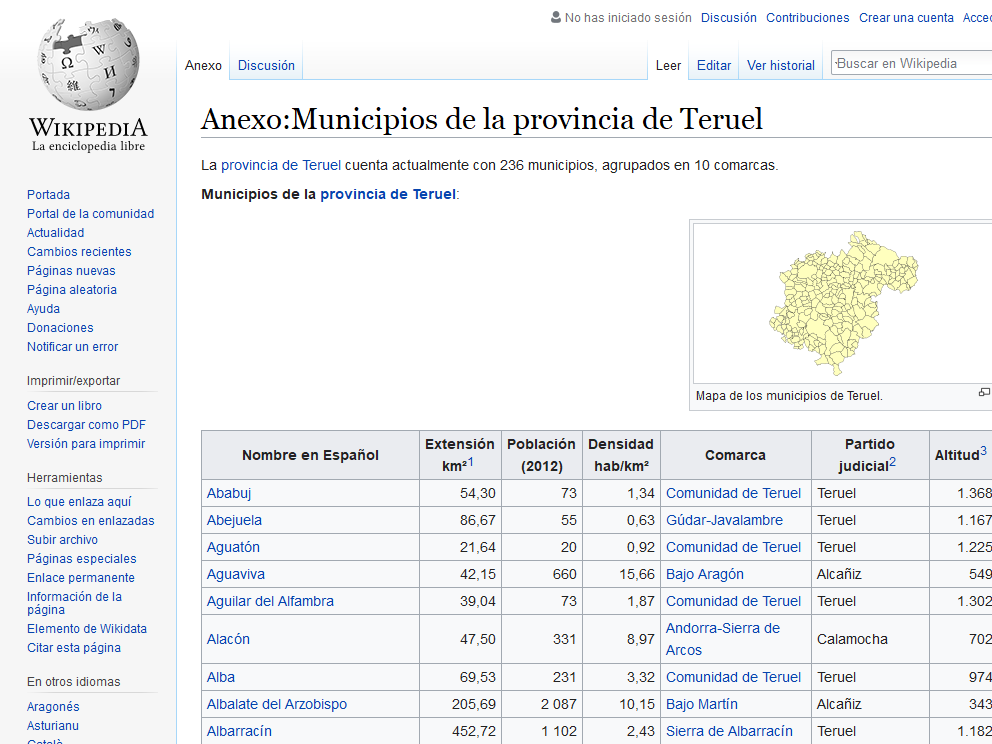
Venga, a bajarnos la información de la tabla. Para ello usaré la función rvest::read_html() que: parses the html page of the given url and saves the result as an xml object. Después queda seleccionar la información que necesitas con html_nodes() para después extraer el texto con `html_text()
library("rvest")
library("tidyverse")
content <- read_html("https://es.wikipedia.org/wiki/Anexo:Municipios_de_la_provincia_de_Teruel")
head <- content %>% html_nodes('head')
head <- content %>% html_nodes('head') %>% html_text()Con la función rvest::html_nodes() se puede extraer pieces out of HTML documents using XPath and css selectors. Mirando el código fuente de la página web veo que cada municipio está en un elemento como: <a href="/wiki/Ababuj" title="Ababuj">Ababuj</a> dentro de una tabla.
Mirando el código fuente de la página web, se ve que solo hay una tabla, así que con el chunk de abajo podríamos seleccionar la tabla que quiero, pero lo tendríamos como texto.
body_table <- content %>% html_nodes('body') %>%
html_nodes('table') %>%
html_nodes('td') %>% html_text()Así que usaré la función html_table()
body_table <- content %>% html_nodes('body') %>%
html_nodes('table') %>%
html_table()
Teruel <- body_table[[1]]Ya tenemos la tabla, pero hay varios problemas:
- en la columna de altitudes, los datos tienen un punto que separa los miles, y la función
html_tablelo interpreta como un punto decimal. Esto lo he solucionado conhtml_table(dec = ","). Pero luego tocará quitar los puntos de separación de miles. También hay un problema con los nombres de las columnas: son no estándar, tienen caracteres raros.
body_table <- content %>% html_nodes('body') %>%
html_nodes('table') %>%
html_table(dec = ",")
Teruel <- body_table[[1]]Primero arreglo el problema con el nombre de las variables, pero a capón con names()
names(Teruel) <- c("Nombre", "Extension", "Poblacion", "Densidad", "Comarca", "Partido_judicial", "Altitud")Ahora quito los puntos que señalizan los millares. Los quito con Altitud = str_replace_all(Altitud,"[[:punct:]]", ""). A lo bestia.
library(stringr)
Teruel <- Teruel %>% map(str_trim) %>% as.tibble() #- quita caracteres al final
Teruel <- Teruel %>% mutate(Altitud = str_replace_all(Altitud,"[[:punct:]]", "")) Sólo queda ordenar los pueblos por la variable Altitud
Teruel <- Teruel %>% mutate(Altitud = as.double(Altitud)) %>%
arrange(desc(Altitud))Ya podemos imprimir los resultados… y los 4 pueblos/municipios más altos de Teruel son:
#devtools::install_github("perezp44/personal.pjp")
library(personal.pjp)
library(knitr)
library(kableExtra)
aa <- Teruel %>% select(1,3,5,7) %>% slice(1:4)
#knitr::kable(aa, digits = 2, align = "c", caption = "Los 4 municipios de Teruel con más altitud" )
kable(aa, "html", digits = 2, caption = "Los 4 municipios de Teruel con más altitud") %>%
kable_styling(bootstrap_options = c("striped", "hover"))| Nombre | Poblacion | Comarca | Altitud |
|---|---|---|---|
| Valdelinares | 106 | Gúdar-Javalambre | 1692 |
| Griegos | 143 | Sierra de Albarracín | 1601 |
| Gúdar | 77 | Gúdar-Javalambre | 1587 |
| Bronchales | 472 | Sierra de Albarracín | 1569 |
Hecho!! Valdelinares con 1692 metros es el campeón. Griegos el segundo. Tengo que ir a Griegos!!!!
La tabla más mejor:
library(DT)
aa <- decimales_df_pjp(Teruel, 2) %>% select(1,7,3,5) #- rtdos con 2 decimales
datatable(aa, extensions = 'Scroller', options = list( pageLength = 10, deferRender = TRUE,scrollY = 400,scroller = TRUE), rownames = F, filter = "top" )Otra forma de hacer lo mismo
En lugar de con CSS selector se pueden usar xpath para seleccionar las partes de la página web que quieres bajar. Resulta que con el CSS selector vi que la xpath de la tabla es: /html/body/div[3]/div[3]/div[4]/div/table. Sí, de momento para mi también es pura magia.
url <- 'https://es.wikipedia.org/wiki/Anexo:Municipios_de_la_provincia_de_Teruel'
Teruel <- url %>%
read_html() %>%
html_nodes(xpath='/html/body/div[3]/div[3]/div[4]/div/table') %>%
html_table(dec = ",")
Teruel <- Teruel[[1]]Entendiendo lo que he hecho
Pues he hecho web scrapping. He bajado una tabla de la wikipedia y me la he traído a R como un dataframe.
Las partes quieres bajar se pueden seleccionar con CSS selectors o con xpaths
He conseguido coger la tabla pero a capón, vamos que no me entero mucho … aún; así que algún día tendré que leer la vignette de rvest y de allí te lleva a este tutorial sobre CSS selectors. También habrá que mirar vignette("selectorgadget")
Ahora tocaría hacer un mapa con los pueblos de Teruel coloreados según su altitud, pero lo dejo para el próximo post, que como es un reciclado de R & flowers 4, pues ya lo tengo hecho.
Bye